




蜂集采集器jQuery选择器采集教程
蜂集采集器是WordPress上非常强大的内容采集器,能采集器普通咨讯站,资源站,下载站,产品站等。
很多人不太了解规则应该怎么写。其实这款采集器可以使用非常简单jQuery选择器。这篇教程教大家如何使用jQuery表达式采集网页内容。
在教程开始之前,我们需要先简单学习一下jQuery表达式。
jQuery表达式
这里我们主要介绍四种:
1. id选择器: #id1 根据id属性为id1的节点
2. class选择器: .class-name 选择class属性为class-name的所有节点
3. 节点选择器: element 选择名为element的所有节点
4. 层级选择器: #id1 .class-name 选择id属性为id1下面的所有class为class-name的节点
以下面的html为例子
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>demo</title>
</head>
<body>
<div class="container">
<div id="notMe"><p>id="notMe"</p></div>
<div id="myDiv">
<a href="http://www.imwpweb.com">imwpweb</a>
</div>
</div>
</body>
</html>
使用id选择器 “#myDiv”选择的节点则是
<div id="myDiv"><a href="http://www.imwpweb.com">imwpweb</a></div>使用class选择器 “.container” 选择的节点则是
<div class="container">
<div id="notMe">
<p>id="notMe"</p>
</div>
<div id="myDiv">
<a href="http://www.imwpweb.com">imwpweb</a>
</div>
</div>使用层级选择器”#myDiv a”
<a href="http://www.imwpweb.com">imwpweb</a>jQuery选择器就是这么简单!
总结一下:网页中的标签中有id,那么用”#”后面接着id这个属性值。如果有class,那么用 “.”后面接着class这个属性值。
列表采集规则
了解jQuery选择器,那么蜂集采集器的采集规则就不难写了。
首先学习列表规则。所谓列表规则就是从目标网页中获取文章列表的规则。只有采集到了文章列表,我们才能进一步采集文章内容。
下图就是一个列表规则,表达式是 “.list a”
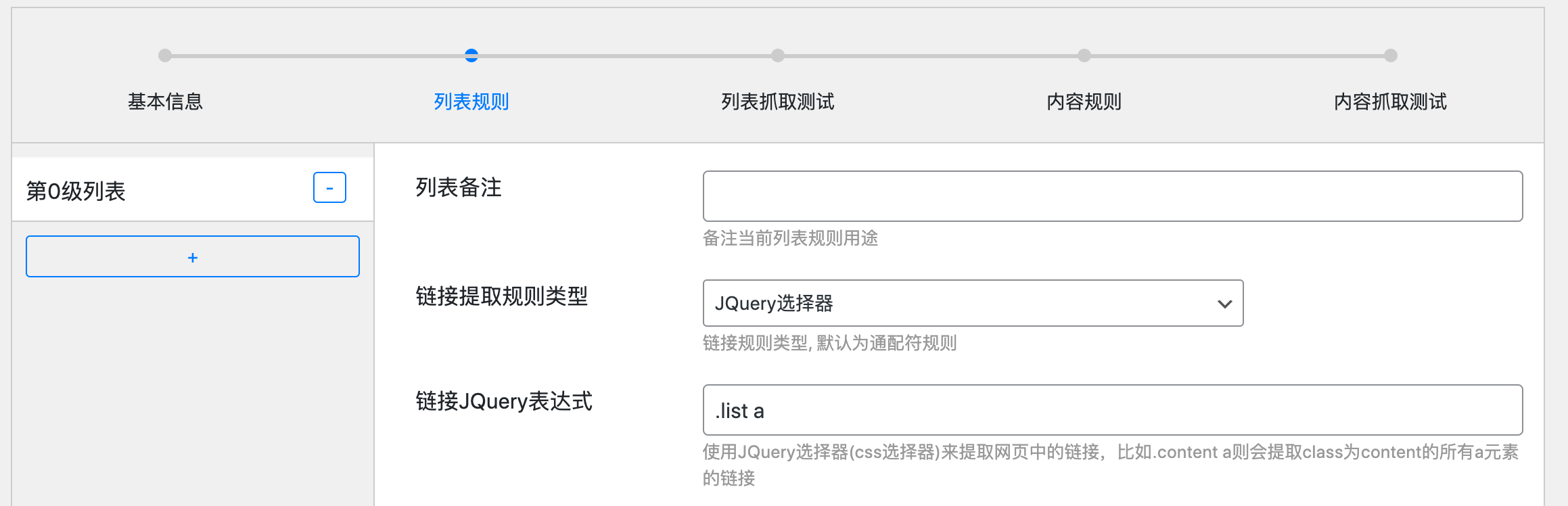
根据我们上面学习的jQuery表达式,”.list a”的含义就是选择 class为list容器下面的a元素,也就是list下面所有的链接,这个链接就是我们的文章列表。
比如我们有下面这样的列表
<ul class="list">
<li><a href="1.html">列表项目一</a></li>
<li><a href="2.html">列表项目二</a></li>
<li><a href="3.html">列表项目三</a></li>
</ul>那么上面 .list a 这个规则采集到的就是 1.html 2.html 3.html 这几个文章地址。有了文章地址,我们才能继续采集文章。记住,蜂集采集器的工作模式是:从入口发现文章列表,再采集文章列表发布成文章。
如果不会查看网页源代码,可以前往:如何查看网页源代码教程中学习。
内容规则
内容规则指的是我们采集的文章所需要的规则,包含:标题,正文,分类等。我们需要为每个字段设置相应的规则!
在标题采集中,我们的jQuery选择器是h1,表示采集的是目标网站的<h1>标签中的内容。一般标题都是h1。
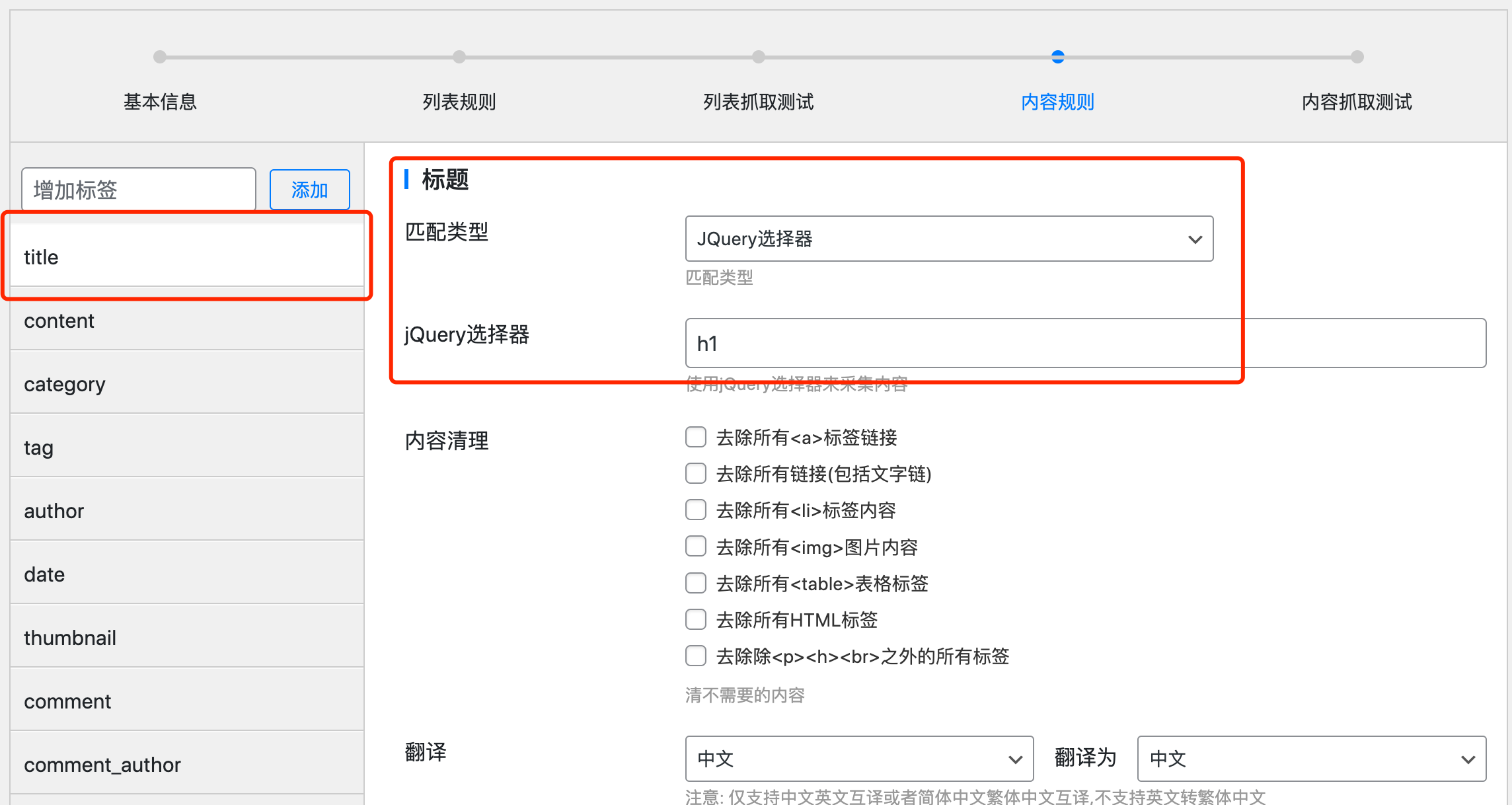
同样,正文,分类我们都可以此类推。填写相应的jQuery选择器即可采集。如果不会查看网页源代码,可以前往:如何查看网页源代码教程中学习。
新版新增Attr属性采集
最新版采集器新增Attr属性,用来采集链接更方便了。
比如我们想采集图片的地址,之前只能用正则表达式匹配,jQuery表达式无法做到。现在增加attr属性提取规则,可以很方便提取html标签属性。
比如我们有个网页中缩略图部分
<div class="thumb">
<img src="thumb.png" />
</div>想要采集到thumb.png,那么规则可以这样写
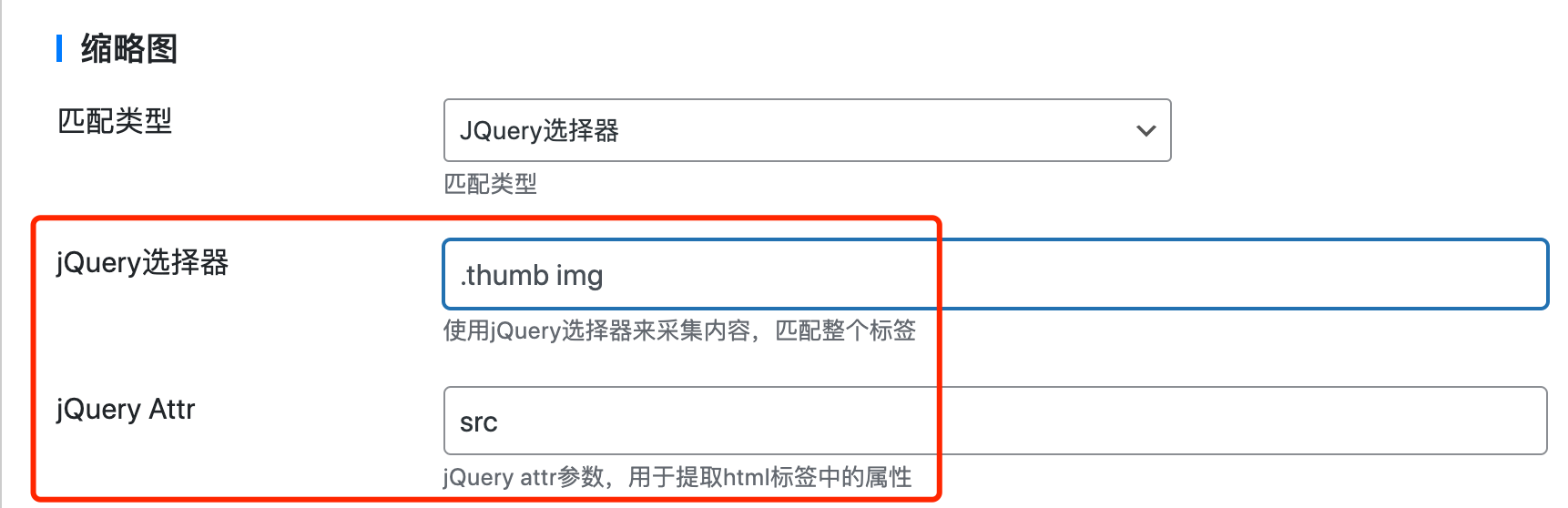
这个意思就是选择.thumb下img标签中的src属性值。是不是非常简单呢?
jQuery选择器参考手册
| 选择器 | 实例 | 选取 |
|---|---|---|
| * | $(“*”) | 所有元素 |
| #id | $(“#lastname”) | id=”lastname” 的元素 |
| .class | $(“.intro”) | 所有 class=”intro” 的元素 |
| element | $(“p”) | 所有 <p> 元素 |
| .class.class | $(“.intro.demo”) | 所有 class=”intro” 且 class=”demo” 的元素 |
| :first | $(“p:first”) | 第一个 <p> 元素 |
| :last | $(“p:last”) | 最后一个 <p> 元素 |
| :even | $(“tr:even”) | 所有偶数 <tr> 元素 |
| :odd | $(“tr:odd”) | 所有奇数 <tr> 元素 |
| :eq(index) | $(“ul li:eq(3)”) | 列表中的第四个元素(index 从 0 开始) |
| :gt(no) | $(“ul li:gt(3)”) | 列出 index 大于 3 的元素 |
| :lt(no) | $(“ul li:lt(3)”) | 列出 index 小于 3 的元素 |
| :not(selector) | $(“input:not(:empty)”) | 所有不为空的 input 元素 |
| :header | $(“:header”) | 所有标题元素 <h1> – <h6> |
| :animated | 所有动画元素 | |
| :contains(text) | $(“:contains(‘imwpweb’)”) | 包含指定字符串的所有元素 |
| :empty | $(“:empty”) | 无子(元素)节点的所有元素 |
| :hidden | $(“p:hidden”) | 所有隐藏的 <p> 元素 |
| :visible | $(“table:visible”) | 所有可见的表格 |
| s1,s2,s3 | $(“th,td,.intro”) | 所有带有匹配选择的元素 |
| [attribute] | $(“[href]”) | 所有带有 href 属性的元素 |
| [attribute=value] | $(“[href=’#’]”) | 所有 href 属性的值等于 “#” 的元素 |
| [attribute!=value] | $(“[href!=’#’]”) | 所有 href 属性的值不等于 “#” 的元素 |
| [attribute$=value] | $(“[href$=’.jpg’]”) | 所有 href 属性的值包含以 “.jpg” 结尾的元素 |
| :input | $(“:input”) | 所有 <input> 元素 |
| :text | $(“:text”) | 所有 type=”text” 的 <input> 元素 |
| :password | $(“:password”) | 所有 type=”password” 的 <input> 元素 |
| :radio | $(“:radio”) | 所有 type=”radio” 的 <input> 元素 |
| :checkbox | $(“:checkbox”) | 所有 type=”checkbox” 的 <input> 元素 |
| :submit | $(“:submit”) | 所有 type=”submit” 的 <input> 元素 |
| :reset | $(“:reset”) | 所有 type=”reset” 的 <input> 元素 |
| :button | $(“:button”) | 所有 type=”button” 的 <input> 元素 |
| :image | $(“:image”) | 所有 type=”image” 的 <input> 元素 |
| :file | $(“:file”) | 所有 type=”file” 的 <input> 元素 |
| :enabled | $(“:enabled”) | 所有激活的 input 元素 |
| :disabled | $(“:disabled”) | 所有禁用的 input 元素 |
| :selected | $(“:selected”) | 所有被选取的 input 元素 |
| :checked | $(“:checked”) | 所有被选中的 input 元素 |
你可能还喜欢下面这些文章
 蜂集如何使用jQuery选择器采集网页内容
蜂集如何使用jQuery选择器采集网页内容
的元素.class$(".intro")所有。visible")所有可见的表格s1,s2,s3$("th,td,.intro")所有带有匹配选择的元素$("")所有带有。
 蜂集采集器,一款全自动的wordpress采集插件
蜂集采集器,一款全自动的wordpress采集插件
imwprobot(蜂集)是一款功能强大的全自动智能采集插件,专为WordPress设计。它能在服务端自动运行,无需人工监督或额外的电脑环境。主要特点包括全自动无人值守定时采集、自动同步目标站更新、AI自动生成关键词和摘要等。蜂集支持多种站点
 如何编写蜂集的采集模块
如何编写蜂集的采集模块
测试采集当所有的规则都编写完毕之后,我们需要验证一下采集器是不是可以根据该规则正确采集,进入测试抓取Tab,填写链接和页面层级,点击抓取测试,查看效果,如下图:如果对采集器有使用上的疑惑,可以到蜂集采集交流群(群号在采集器的关于我们中可以找到
 当HTML 中有多个class属性会出现什么问题
当HTML 中有多个class属性会出现什么问题
当一个元素有多个属性时会发生什么。如果您知道将类添加到此代码段(WordPress。解决方案当一个元素有多个类属性时会发生什么。”如果您知道将类添加到此代码段(WordPress。

 蜂集设置采集分页列表方法
蜂集设置采集分页列表方法
首先我们需要找到分页链接和其他链接不一样的地方,例子中的分页的链接都有“page”这个单词而其他的链接都没有这个单词,那么我们在列表规则中的链接包含框填上“page”,这样就可以采集到所有的翻页链接,如下图:填写完了之后,我们将测试的链接填入
 wordpress支持采集吗
wordpress支持采集吗
wordpress本身并没有采集功能,不过可以通过插件来实现采集功能,目前wordpress上比较好的采集插件是imwprobot(蜂集采集),可以实现全自动采集,虚拟主机也可以运行。
 蜂集采集如何进行全站采集
蜂集采集如何进行全站采集
比如我们使用首页测试一下抓取,可以看到下面抓取了很多链接我们再用内部文章页面测试抓取,可以看到下面依然有新的链接第二步:设置正文规则如果你懂XPath或者正则,那么写一个抓取正文的规则是一件很容易的事情。