




如何用浏览器获取XPath规则,蜂集XPath使用指南
蜂集采集器现在内置了一个非常方便的匹配规则——XPath!XPath的方便之处就在于可以用浏览器直接提取出来。
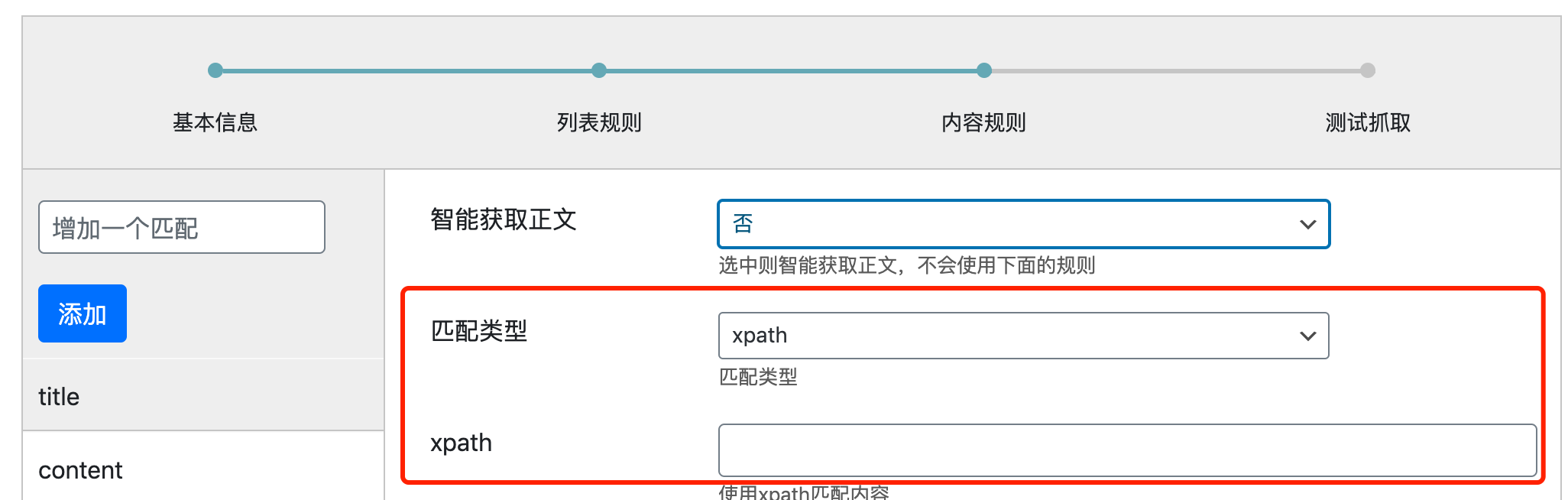
如何用浏览器提取XPath
使用chrome浏览器打开你想采集的网址。进入浏览器的开发者模式(windows系统按F12,MAC系统按cmd+option+i)。点击页面节点选择按钮(方框半包住箭头的按钮),然后到右侧的源代码栏,点击右键,就可以看到copy full xpath
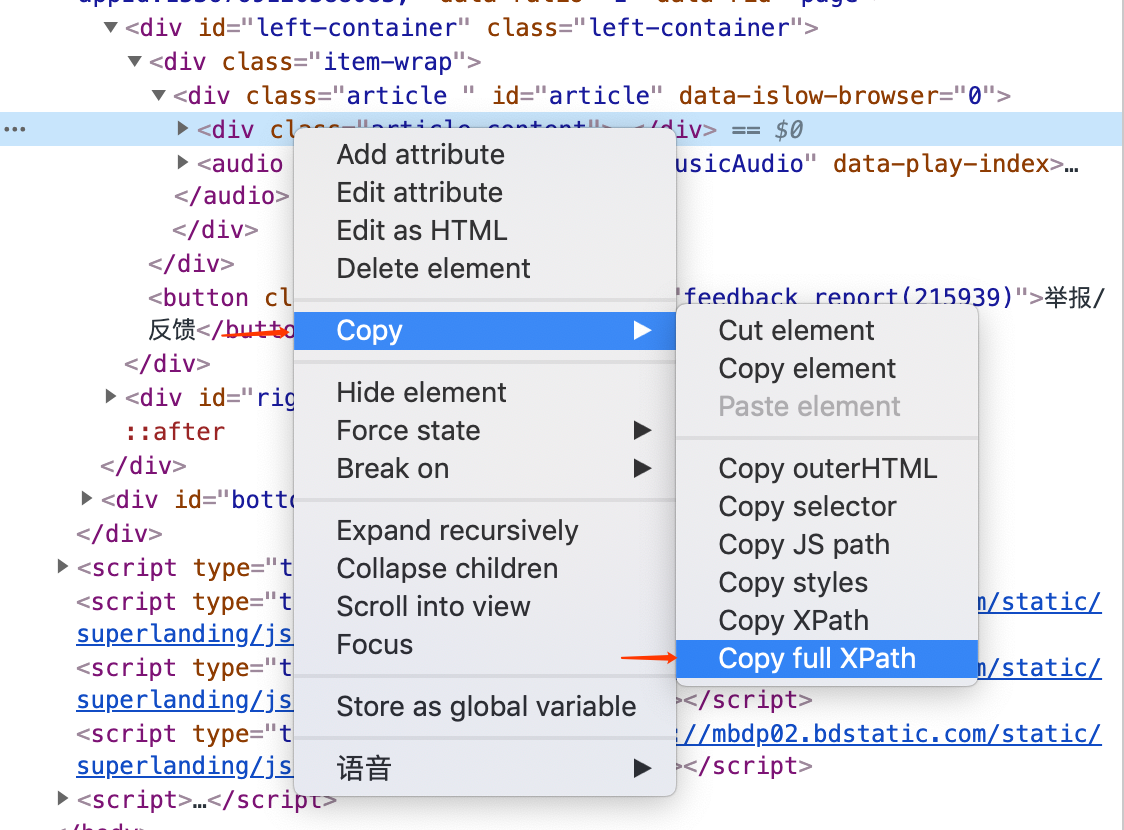
为了避免div层级变化,可以用copy XPath来代替copy full XPath。
测试XPath
把提取到的XPath复制到规则中
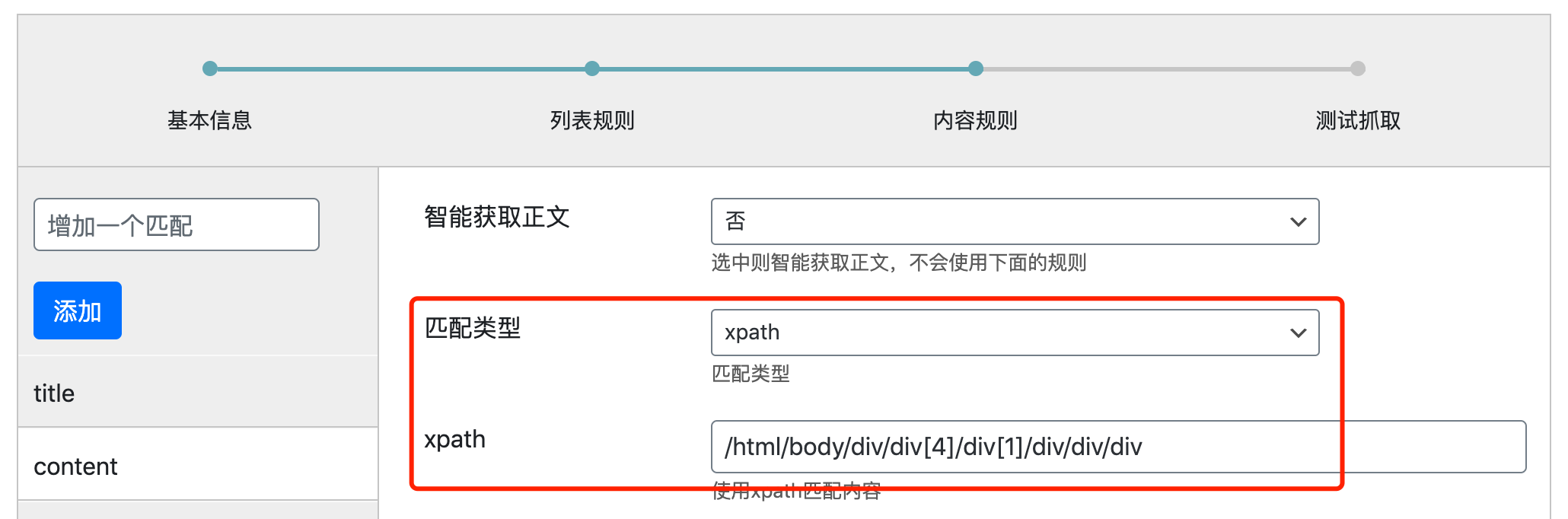
点击测试抓取
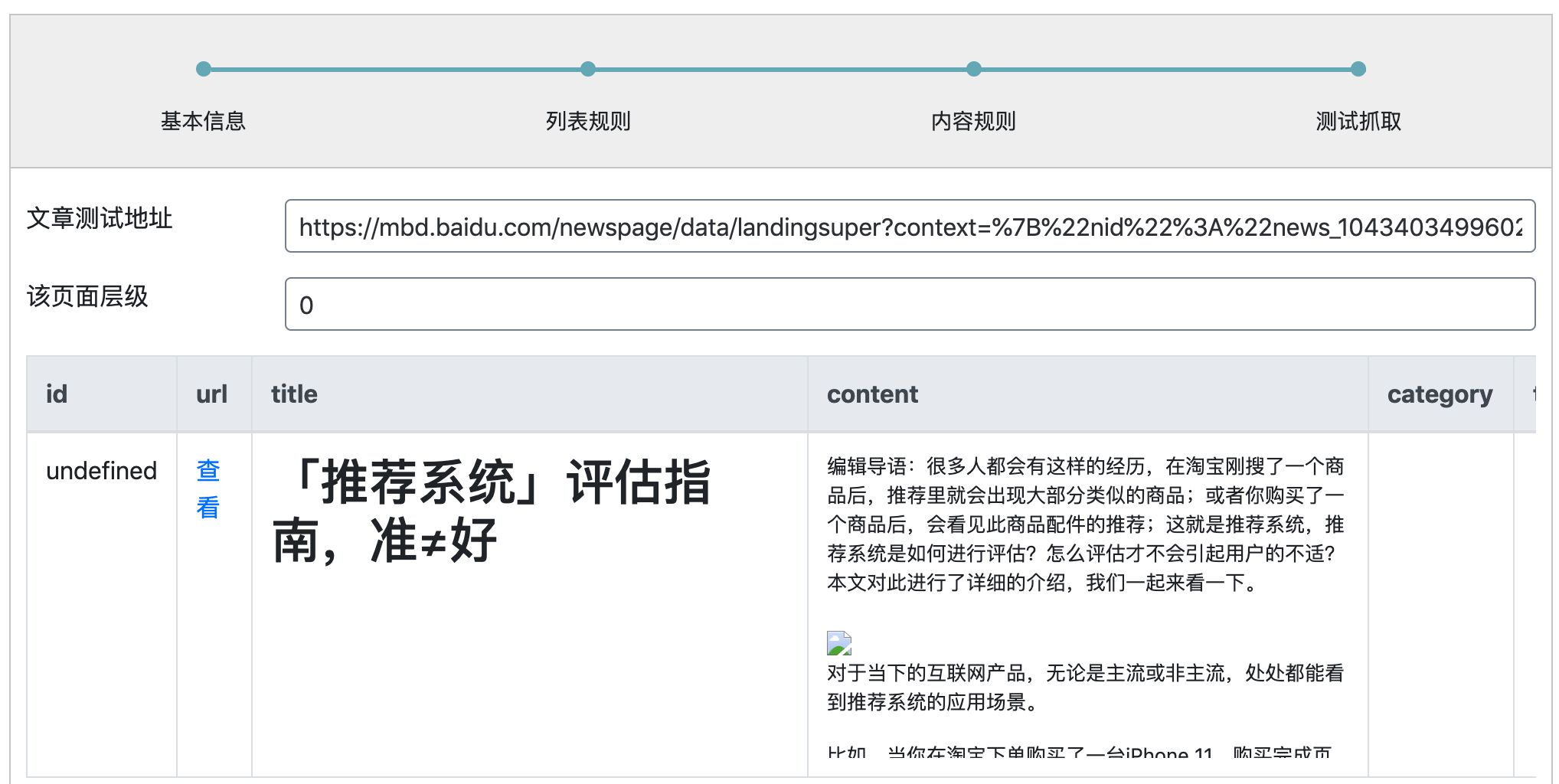
由于有些占站点做了防盗链,直接采集时候可能图片不会展示,不过采集下来的时候,图片会自动本地化,此时图片可以展示。
到此,你就学会了使用浏览器提取xpath方法。
你可能还喜欢下面这些文章
 如何获取网站的Cookie
如何获取网站的Cookie
方法第一步:使用chrome浏览器,打开目标网站。将会打开浏览器的开发者模式,切换到网络tab,再刷新网页。将会打开如下页面:选中首页,在请求标头中Cookie后面的一串字符串就是网站的cookie。
 WordPress 文章自动配图、缩略图插件 WPAC 介绍与下载
WordPress 文章自动配图、缩略图插件 WPAC 介绍与下载
2、自动生成的图片并非真实在磁盘中的图片,而是动态生成的,如果保存到磁盘会占用大量空间,这个空间没必要浪费,因此修改主题代码,直接将缩略图的地址改为wpac自动生成的缩略图地址是一个非常好的方案。
 蜂集采集器,一款全自动的wordpress采集插件
蜂集采集器,一款全自动的wordpress采集插件
imwprobot(蜂集)是一款功能强大的全自动智能采集插件,专为WordPress设计。它能在服务端自动运行,无需人工监督或额外的电脑环境。主要特点包括全自动无人值守定时采集、自动同步目标站更新、AI自动生成关键词和摘要等。蜂集支持多种站点
 如何使用XPath采集网页
如何使用XPath采集网页
为例子,点击开发者工具中的小箭头,如下图:然后鼠标放到网页中寻找需要采集的区域,在右侧中对应的源代码会被高量显示,如下图所示:因此我们左侧选中的区域的class就是content,写成xpath如下:意思就是匹配根结点下面任意class名称为
 如何编写蜂集的采集模块
如何编写蜂集的采集模块
测试采集当所有的规则都编写完毕之后,我们需要验证一下采集器是不是可以根据该规则正确采集,进入测试抓取Tab,填写链接和页面层级,点击抓取测试,查看效果,如下图:如果对采集器有使用上的疑惑,可以到蜂集采集交流群(群号在采集器的关于我们中可以找到
 为什么WordPress网站移动端图片无法自适应
为什么WordPress网站移动端图片无法自适应
当手机访问WordPress网站时,图片溢出或变形的问题会直接导致62%用户流失。本文深度解析移动端图片失配的根源:固定像素尺寸与响应式需求的冲突,并提供四套解决方案:1)通过CSS注入强制响应式规则(需处理主题样式覆盖);2)使用Smush
 如何通过WordPress优化移动端图片自适应
如何通过WordPress优化移动端图片自适应
如何优化WordPress移动端图片自适应?在移动设备占比超60%流量的当下,桌面端完美的图片常因分辨率差异在手机上出现模糊、变形或加载缓慢问题,影响用户体验与SEO。本文提供无需编码的解决方案:首先调整WordPress媒体设置,合理配置图
